Creating a Named Entity Recognition Pipeline for the Soul of Reason Radio Program
December 18, 2020
By Nyla Ennels
Introduction

In this post, I discuss my experience working on the Soul of Reason collection as a Junior Data Scientist through the DS3 initiative at NYU’s Center for Data Science. Soul of Reason was a thirty-minute radio program that aired from 1971 to 1986 on WNBC and on the University’s radio station, WNYU; there are currently over a hundred recordings. The show was hosted by Dr. Roscoe C. Brown, Jr., a former NYU professor and director of the Institute of Afro-American Affairs. Soul of Reason features Dr. Brown’s conversations with a variety of figures, ranging from politicians and activists to artists and performers, in New York City during the Civil Rights and Black Power movements. The show was primarily focused on topics and organizations affecting the African-American, Puerto-Rican and African communities.2
The Case for Named Entity Recognition
The Soul of Reason radio recordings have been transcribed thanks to the community transcription events hosted by NYU Libraries. Before beginning the project, I read many of the transcripts to gain a better understanding of the radio show, and I was astounded by all of the rich historical information these transcripts contained. In one particular episode, I learned of a historical Black community known as Weeksville. This community, located in present-day Bedford-Stuyvesant, was a thriving town of free African-Americans during slavery in the 1800s.
Similar to this excerpt, each thirty-minute episode of the Soul of Reason assortment contains historically-rich information and expert commentary that researchers and curious individuals may wish to leverage. Given the considerable number of recordings/transcripts, it would be inefficient for any human to manually extract all of the topics of interest from each document. This is where Natural Language Processing (NLP), and in particular Named Entity Recognition (NER), prove to be especially useful; NER is a technique used to automatically identify and extract relevant entities from a corpus. Extracting pertinent entities from the Soul of Reason collection allows for the publication of an open database of these entities and provides the opportunity for continued research.
Creating the Pipeline

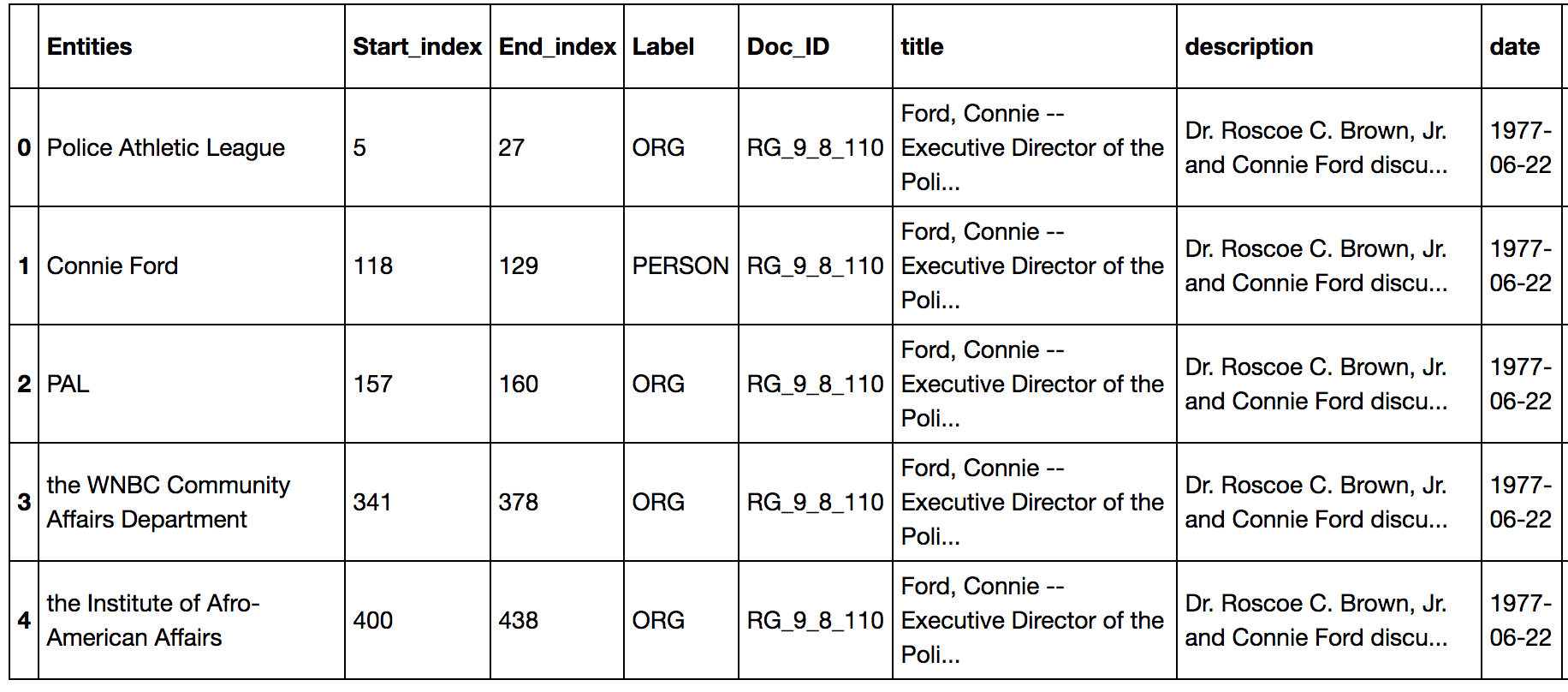
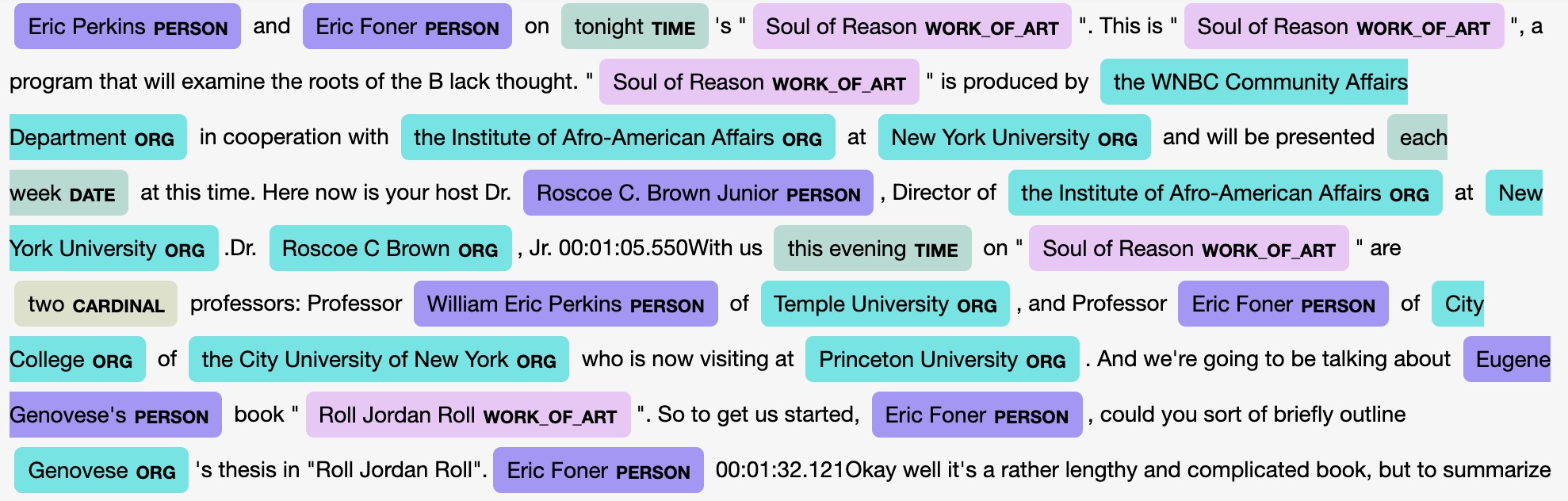
The first step in the pipeline is a function that imports all of the transcript files into Python as a list. After this is completed, the timestamps/speaker-lines are removed from each transcript so that speakers are not unnecessarily duplicated in the final dataset. Next, the document ID for each transcript is appended to its corresponding text in Python: this allows the master metadata file to be joined later. The model then predicts the entities from each transcript and returns them as a list, along with their beginning and ending Python index, unique transcript identifier and entity label. The entity label describes what type of entity has been extracted; examples include: person, organization, date, and work of art, among other label types. Finally, the last step in the pipeline is to construct the final dataset. This is achieved by joining the master metadata file on the aforementioned predictions and labels, as seen in Figure 2 below. Statistics such as the number of unique entities and the number of entities by label type are also returned once the model completes its predictions. In addition, an entity visualizer was implemented, allowing one to see the entities highlighted in a document and filter by label type. Error-handling is included in every function to manage possible incorrect inputs, typos or inconsistent file types.
Model Selection
Two primary models were tested when searching for the best NER model: the first being a pre-trained BERT model, and the second a pre-trained spaCy model. To evaluate the performance of each, several transcripts were annotated by hand with the correct entities and labels to be used as a test set on each of the models. The test examples showed that the spaCy model performed best. I attempted to fine-tune this spaCy model, but unfortunately encountered the catastrophic-forgetting probelm. Resolving this issue proved to be time-consuming and tedious; therefore, the final model was the non-fine-tuned spaCy pre-trained model, which nonetheless proved to be accurate.
Accommodating Various Technical Backgrounds
The completed code was written as a Python class in a Jupyter Notebook, with each method requiring specific input(s). To make this deliverable more accessible to those without Python coding experience, I created both a command-line script and web-browser application to perform the same tasks as the Jupyter Notebook code. Each method downloads both a csv and a json file of predicted entities to one’s computer after providing two simple file path inputs.

Completing this project allowed me to expand my knowledge of history, data science and NLP. It has also reminded me why initiatives such as the Soul of Reason collection play a critical role in preserving history and providing useful data to all.
-
Springfield College. “Roscoe Brown (October 7, 1970).” Archives and Special Collections, 22 Oct. 2012. https://springfieldcollege.contentdm.oclc.org/digital/collection/p15370coll2/id/5279/ ↩